- Cos’è un thread?
- C’erano una volta i thread di piattaforma
- Thread e richieste
- Thread bloccati
- La soluzione asincrona
- Lightweight Thread
- Thread virtuali
- Thread a basso costo e in grande disponibilità
- Visibilità e scope
- Show me the code!
- Performance a confronto
- Riferimenti
- Conclusioni
Una delle feature più eccitanti dell’ultima versione di Java rilasciata poco più di un mese fa è certamente la finalizzazione dei thread virtuali. La feature era già stata proposta in preview nelle versioni 19 e 20 e giunge adesso alla sua forma finale e definitiva. Andiamo a vedere cosa sono i thread virtuali e come cambiano il panorama dell’ecosistema Java!
Cos’è un thread?
Semplificando molto, un thread si può immaginare come una serie di istruzioni con stato di esecuzione indipendente all’interno di un altro processo. In un software semplice, una singola istruzione viene eseguita in un dato momento per volta, ma programmi più complessi possono lavorare su più “attività” contemporaneamente: ad esempio è possibile interrogare un database e contemporaneamente leggere un file per poi aggregare i due set di dati per ulteriori elaborazioni. Ognuna di queste attività che procede in modo indipendente in parallelo alle altre è rappresentata da un thread.
C’erano una volta i thread di piattaforma
Prima dell’introduzione dei thread virtuali, quelli a cui eravamo abituati erano i cosiddetti thread di piattaforma ovvero mappati 1 a 1 con i thread kernel schedulati dal sistema operativo della macchina in cui viene eseguito il programma. Questi thread sono abbastanza pesanti: a seconda della configurazione e del sistema operativo, il loro consumo di memoria oscilla tra i 2 e i 10 MB di RAM. Immaginiamo ora di volere realizzare un’applicazione che gestisca un milione di operazioni concorrenti (non è un’iperbole: pensate ad esempio ad un software di trading che deve processare un numero decisamente elevato di operazioni al secondo): facendo un rapido calcolo servirebbe una macchina con almeno 2 TB di RAM per non rischiare di collassare.
Thread e richieste
Questo limite quindi si adatta ha conseguenze immediate nel modello client – server che conosciamo: ogni request del client normalmente viene gestita utilizzando un singolo thread. Questo ha molti vantaggi perchè rende semplice la gestione dello stato e delle risorse utilizzate dal programma, ma pone vincoli di scalabilità importanti: la capacità di soddisfare richieste concorrenti al nostro software è direttamente legata al numero di thread della piattaforma su cui è ospitato. Per questo motivo è molto più facile esaurire i thread disponibili nel sistema che la potenza di calcolo o le capacità di rete.
Thread bloccati
Alcune operazioni, soprattutto in ambito I/O, possono richiedere un tempo di considerevole per la loro esecuzione: pensiamo alla lettura di file o all’accesso dati in un database in cui grosse moli di dati possono impiegare secondi se non addirittura minuti a completare. Per migliorare le performance vorremmo parallelizzare le operazioni, di modo che mentre l’operazione costosa viene portata a termine altre possano essere eseguite. Tuttavia questo si traduce nell’utilizzo di altri thread, concorrendo al rapido consumo sottolineato in precedenza. Alternativamente si possono accodare le operazioni, ma i tempi di risposta crescerebbero in modo decisamente poco conveniente.
La soluzione asincrona
La soluzione tradizionale a questi limiti è quella di considerare l’utilizzo di una programmazione asincrona: in questo modello, ogni parte della richiesta usa un thread preso da un pool (un insieme condiviso di thread) dove può essere rimesso a disposizione una volta terminata la richiesta, limitando la numerosità necessaria. Questo purtroppo ha un prezzo: la programmazione asincrona ha una curva di apprendimento più ripida rispetto al modello sincrono, il codice può diventare complicato da interpretare e il debugging è generalmente più intricato quando si vuole cercare di seguire lo svolgimento di una richiesta su N thread differenti, ognuno col proprio stacktrace.
Da molto tempo Java supporta la programmazione asincrona ed è doveroso menzionare l’API CompletableFuture che cerca di semplificare la gestione dei processi paralleli. Nondimeno si tratta di una API non priva di complessità e meno vicina al modello intuitivo che abbiamo comunemente.
Lightweight Thread
Se da un lato quindi non possiamo aumentare facilmente il numero di thread di piattaforma del sistema, abbiamo di conseguenza bisogno di un livello di astrazione superiore che disaccoppi quella corrispondenza esatta che diventa un collo di bottiglia per la scalabilità, ossia dei thread “leggeri”.
Un thread leggero non è legato ad una particolare piattaforma e non ha in dotazione la preallocazione di memoria importante dei thread tradizionali: sono gestiti dal runtime anzichè dal sistema operativo. In questo modo è possibile averne un numero molto elevato, molto più alto di quanto sarebbe possibile con l’approccio tradizionale. I cosiddetti Lightweight Thread non sono un’invenzione recente: vari linguaggi già li prevedono come Go, Erlang, Haskell e così via.
Thread virtuali
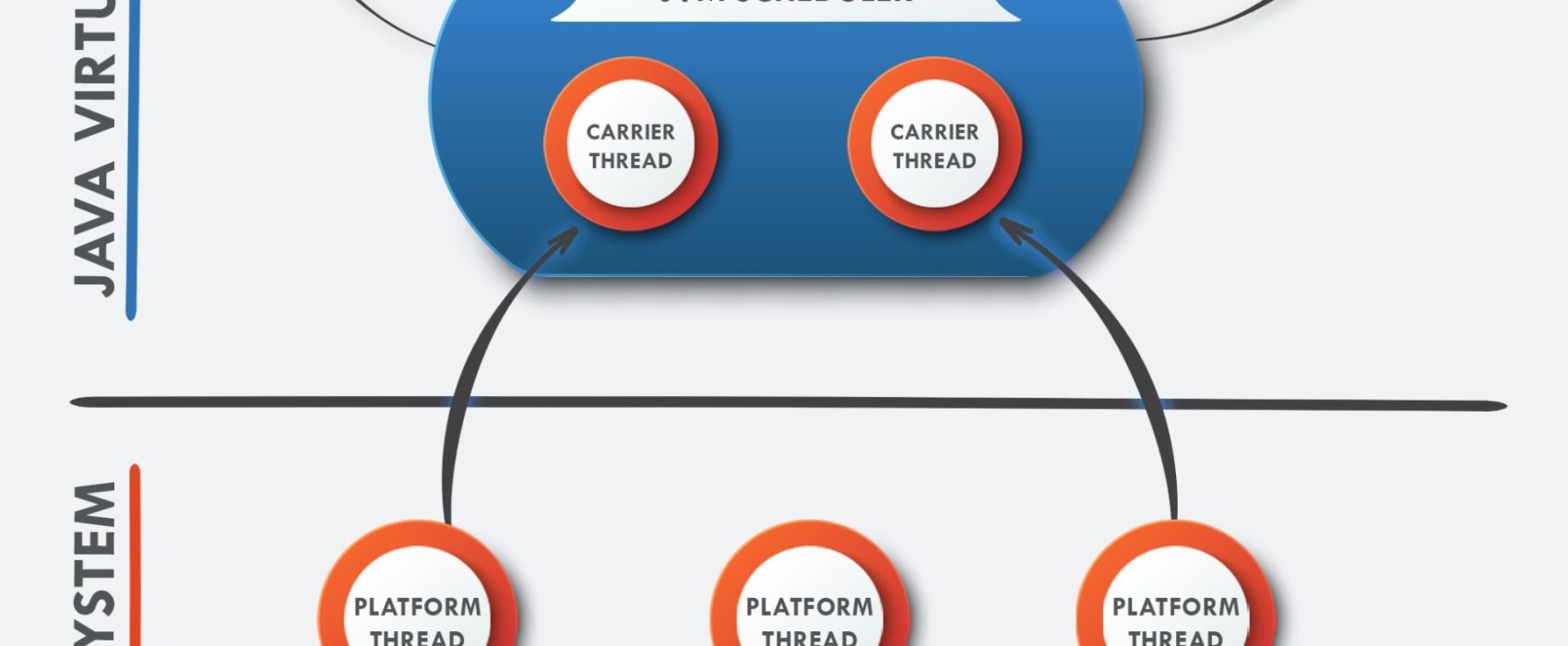
I thread virtuali sono quindi nuovi lightweight thread che sono stati proposti e sviluppati dal Progetto Loom che non vengono gestiti e schedulati dal sistema operativo ma dalla JVM. Naturalmente, in concreto ogni lavoro effettivo dovrà essere eseguito in un thread di piattaforma, ma la JVM utilizza dei thread cosiddetti “carrier” per collegare il thread virtuale nel momento in cui deve eseguire realmente.
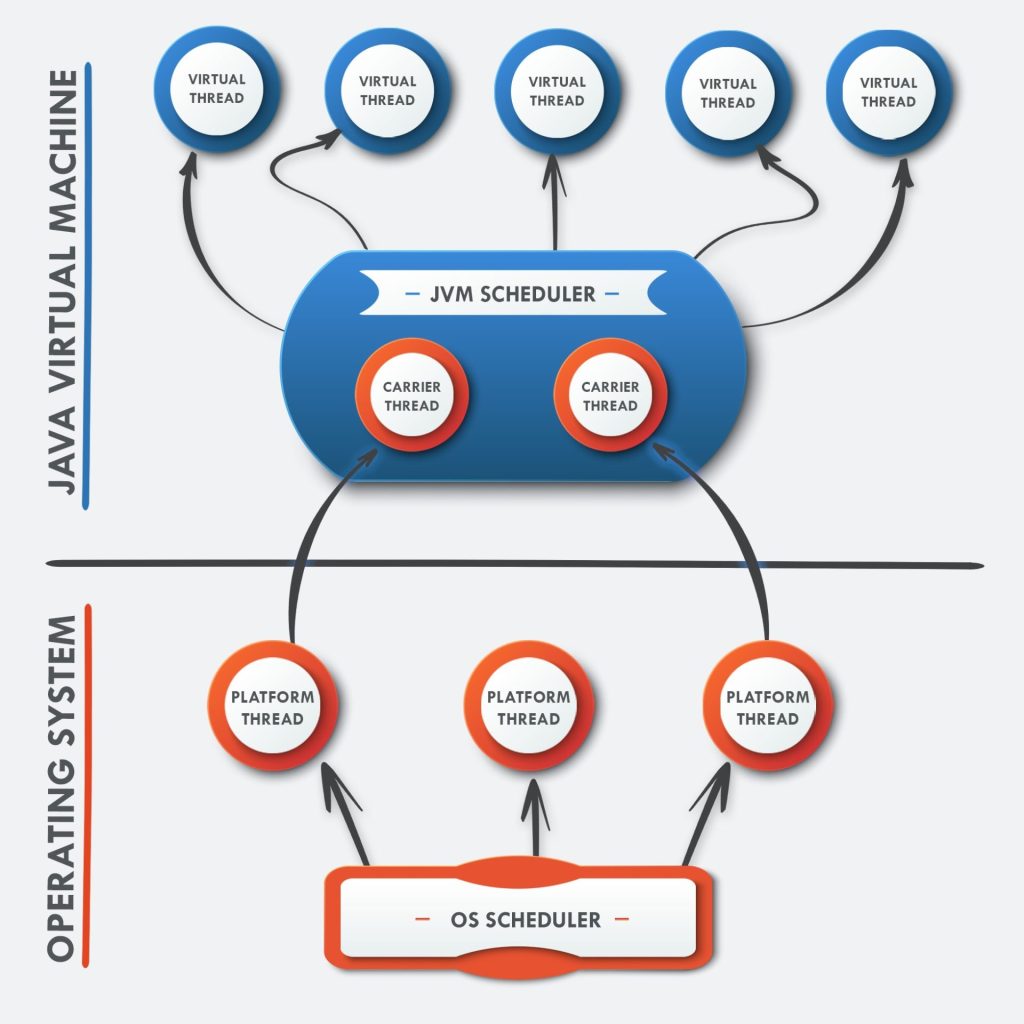
I carrier thread sono gestiti da un ForkJoinPool che lavora in modalita FIFO e work-stealing, a differenza del pool che viene comunemente usato ad esempio nel parallelismo degli Stream dove la strategia utilizzata è LIFO.
Thread a basso costo e in grande disponibilità
In uno scenario come quello che abbiamo appena descritto, utilizzare un modello di concorrenza “un thread per ogni richiesta” riduce notevolmente gli effetti avversi legati ad un alto numero di richieste parallele nel sistema: ogni thread bloccato da una operazione I/O può essere sospeso dalla JVM fino a che esso non sia pronto a riprendere l’attività in seguito. In questo modo il consumo di risorse hardware è altamente ottimizzato, fornendo una elevata scalabilità in termini di concorrenza e throughput. Dal momento che questi thread virtuali sono “economici” non c’è la necessità di organizzarli in pool: ogni task avrà il proprio thread virtuale dedicato.
Visibilità e scope
Lo schedulatore della JVM è responsabile dell’organizzazione dei carrier thread, per cui è necessario imporre alcuni limiti e gradi di separazione per garantire che un numero molto elevato di thread possano eseguire correttamente senza interferire tra di loro. Questo si ottiene separando chiaramente il thread virtuale e il carrier che lo trasporta:
- Un thread virtuale non può accedere al proprio carrier thread e l’istruzione Thread.currentThread() ritorna il thread virtuale stesso
- Ogni stacktrace è separato e di conseguenza le eccezioni lanciate in un thread virtuale includono solo i frame del proprio stack
- Le variabili threadlocal di un thread virtuale sono inaccessibili al carrier e viceversa
- Da un punto di vista puramente di scrittura del codice, la condivisione del thread di piattaforma tra il carrier e il virtual thread è invisibile
Show me the code!
Creazione di un thread di piattaforma
La creazione di un thread di piattaforma è semplice
Runnable fn = () -> {
// your code here
};
Thread thread = new Thread(fn).start();con Project Loom si aggiunge una nuova sintassi:
Thread thread = Thread.ofPlatform().
.start(runnable);è presente anche un’intera API fluent che permette di configurare gli aspetti del thread tramite un builder
Thread thread = Thread.ofPlatform().
.daemon()
.name("my-custom-thread")
.unstarted(runnable);Creazione di un thread virtuale
Anche per i thread virtuali è presente un’API fluent analoga
Runnable fn = () -> {
// your code here
};
Thread thread = Thread.ofVirtual(fn)
.start(); alternativamente al builder, è possibile anche eseguire direttamente un Runnable
Thread thread = Thread.startVirtualThread(() -> {
// your code here
});dove per ricongiungerci al thread principale sarà necessario invocare il metodo .join().
Infine si può utilizzare un Executor:
var executorService = Executors.newVirtualThreadPerTaskExecutor();
executorService.submit(() -> {
// your code here
});Performance a confronto
Verifichiamo il risparmio a livello di risorse garantito dall’uso di thread virtuali confrontandolo con i classici platform thread: prendiamo come caso d’uso endpoint Spring che simula la richiesta ad un servizio con tempo di risposta di 10s
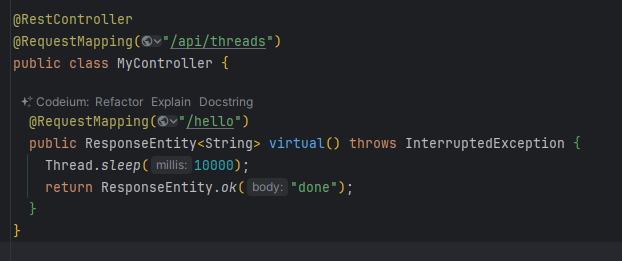
L’applicazione senza ulteriori configurazioni andrebbe ad utilizzare i thread di piattaforma (nota: Tomcat per default limita il numero massimo di thread usati per le richieste ad un valore di default di 200).
Provando a simulare l’accesso simultaneo di 5000 utenti tramite JMeter e monitorando tramite VisualVM il numero di thread utilizzati, vediamo che viene raggiunto il massimo numero di thread con proporzione 1:1
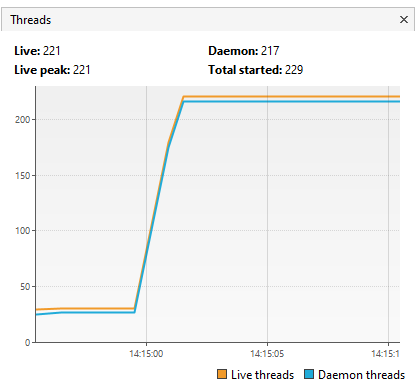
Configurando l’applicazione per utilizzare i thread virtuali invece sono limitati a qualche decina, evitando code (o saturazione del sistema se non fosse per via del limite di sicurezza di Tomcat)
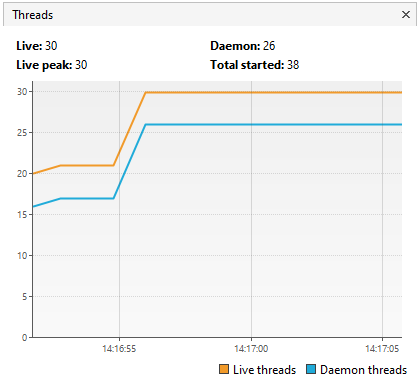
Conclusioni
I thread virtuali aprono la strada al linguaggio Java di poter scrivere applicazioni altamente scalabili utilizzando una struttura semplice e familiare ai developer, senza dover sacrificare per questo le performance o esigere un costo consistente a livello di risorse di sistema.
Le nuove possibilità aperte da questa nuova feature sono sicuramente molto interessanti e gli impatti sull’ecosistema Java non tarderanno a farsi sentire.
Riferimenti
https://www.infoq.com/articles/java-virtual-threads/
https://belief-driven-design.com/looking-at-java-21-virtual-threads-bd181/
https://levelup.gitconnected.com/project-loom-and-virtual-threads-in-java-9569918a7afd
https://blog.rockthejvm.com/ultimate-guide-to-java-virtual-threads/

Redazione EurisIT
EurisIT Tech Insights è il magazine che vi racconta le ultime novità e tendenze nel mondo dell'innovazione e della tecnologia
Last modified: April 23, 2024






