
Pipes and filters è un pattern architetturale del catalogo POSA (Pattern Oriented Software Architecture) nella categoria “Data stream processing”. Un esempio di un’applicazione del genere viene dagli e-commerce, in cui dobbiamo trasformare un flusso di ordini in un flusso di spedizioni (si parla in questo caso di dataflow-driven application) o dalle applicazioni di analisi dei dati.
Indice dei contenuti:
DEFINIZIONE DEL PATTERN
-
Nome
Pipes and filters
-
Scopo
Elaborazione di flussi dati
-
Problema
L’applicazione, o componente, deve trasformare un flusso dati in ingresso in un flusso dati in uscita
-
Soluzione
Suddividi il compito complessivo di elaborazione in una sequenza di passi autocontenuti.
Implementa ciascuna fase dell’elaborazione mediante dei componenti filter. Ciascun filtro consuma dati da un flusso di input e produce dati in un flusso di output, operando una trasformazione parziale e incrementale dell’elaborazione complessiva. Questo permette di evitare la duplicazione del codice, e semplifica la rimozione, la sostituzione o l’integrazione di ulteriori componenti se cambiano i requisiti.
Collega i filtri in una pipeline, mediante dei connettori pipe. Ciascun pipe è un buffer di dati che collega due filtri, mantenendone basso l’accoppiamento.
Nella definizione di questo pattern abbiamo visto l’introduzione di due elementi architetturali, le pipe e i filters. La parola “filter” tuttavia può essere fuorviante, dal momento che suggerisce un qualcosa che seleziona i dati. Qui il termine più corretto sarebbe processor.
Una cosa importante da tenere a mente qui è la coesione dei filtri: ogni filter si deve occupare di un solo compito, e non ci deve essere sovrapposizione tra i compiti dei vari filtri.
I filtri che fanno parte di una pipeline possono essere eseguiti su macchine diverse, e questo, ragionando in un contesto cloud, permette di avvantaggiarsi dell’elasticità di questi ambienti, dal momento che ogni filtro potrebbe scalare indipendentemente dagli altri (specie in contesti come lo scenario 4, che verrà illustrato in seguito). Un filtro che richiede elevata potenza di calcolo può essere eseguito su macchine più potenti, mentre filtri meno “esigenti” possono essere eseguiti su macchine meno costose.
APPLICABILITÀ
Questo pattern può essere impiegato nelle seguenti situazioni:
- L’elaborazione richiesta può essere facilmente suddivisa in step indipendenti
- I diversi step dell’elaborazione hanno requisiti prestazionali (in termini di scalabilità e potenza di calcolo richiesta) differenti
- È richiesta flessibilità in termini di possibilità di cambiare l’ordine dei vari step o di aggiungerne/rimuoverne.
- Si può avere un beneficio nelle prestazioni distribuendo i vari processi su diversi server
- Si vuole una soluzione affidabile che minimizzi le conseguenze del fallimento di uno step
Potrebbe essere controproducente, se non addirittura dannoso, quando:
- Alcuni step dell’elaborazione non sono indipendenti, o devono essere eseguiti insieme come parte della stessa transazione
- Le informazioni relative al contesto o allo stato richieste da uno step rende questo approccio inefficiente, a causa dell’alto numero di informazioni trasferite in seguito al cambio di contesto
I 4 SCENARI POSSIBILI
Ci sono quattro scenari possibili per Pipes and filters: push, pull, push-pull con un solo elemento attivo, push pull con più elementi attivi. I quattro scenari differiscono per la gestione del controllo e degli elementi attivi. Nei primi tre che vedremo c’è un solo elemento attivo. Nel quarto, più complesso (ma anche il più comune) abbiamo più flussi attivi contemporaneamente.
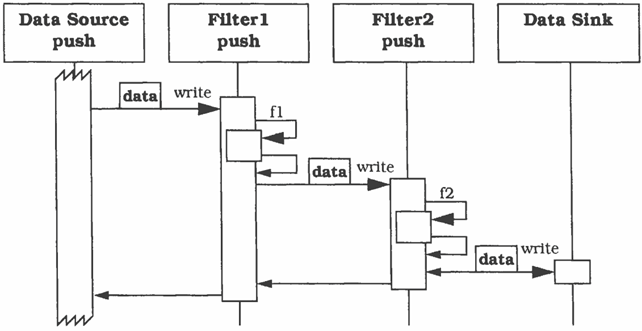
Scenario 1: push
L’elaborazione inizia nella sorgente dati, i filtri sono passivi e le pipe potrebbero essere delle chiamate dirette tra filtri. Un filtro di tipo push definisce un’operazione write, che può essere chiamata dal filtro precedente nella pipeline.
Qui abbiamo la sorgente dati che invia i dati al primo filtro, il quale esegue alcune elaborazioni e le invia a secondo filtro, e così via, fino ad arrivare alla destinazione dati.
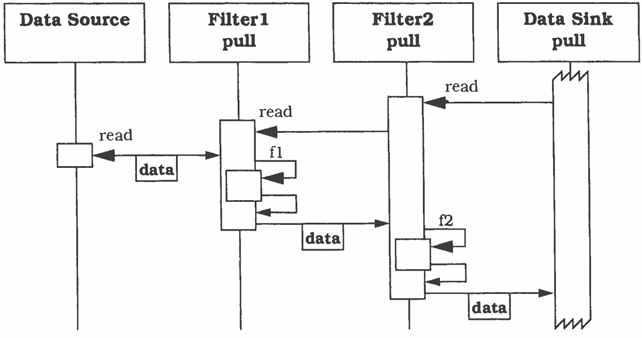
Scenario 2: pull
In questo scenario l’elaborazione inizia nella destinazione dati, i filtri sono sempre passivi e le pipe potrebbero ancora essere delle chiamate dirette tra filtri. Ogni filtro definisce un’operazione read, che diversamente dallo scenario 1 può essere chiamata dal filtro successivo nella pipeline.
Questo scenario è l’inverso del precedente, infatti l’elaborazione parte dalla destinazione finale, che chiede al filtro che la precede di “leggere dei dati”, questo filtro fa la stessa cosa col filtro precedente, e così via fino ala sorgente dati. Qui, come nello scenario precedente, le chiamate sono sincrone, e in questo caso si rischia di bloccare l’elaborazione se uno dei filtri dovesse compiere delle operazioni molto costose, perché ciascun filtro nella catena si trova a dover aspettare i filtri precedenti, mentre nello scenario 1 si potrebbe avere un meccanismo di tipo “fire and forget”, aumentando il parallelismo e quindi le prestazioni (si pensi alle pipeline delle CPU).
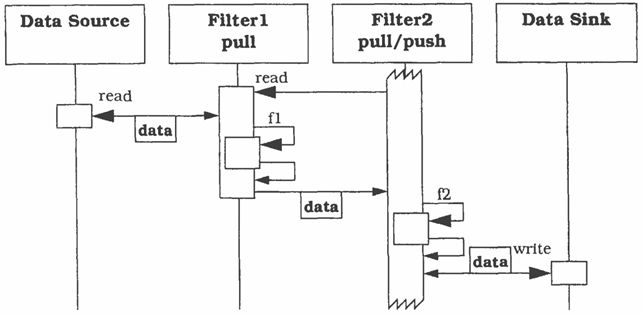
Scenario 3: push-pull con un solo elemento attivo
Qui abbiamo un solo filtro attivo, di tipo pull-push, mentre i filtri che lo precedono nella pipeline sono filtri passivi di tipo pull e quelli che lo seguono sono filtri passivi di tipo push. Un filtro pull-push è un filtro che, ripetutamente, raccoglie dati dai filtri che lo precedono e inviano dati ai filtri che lo seguono.
Scenario 4: push-pull con più elementi attivi
In quest’ultimo scenario, che è il più comune dei quattro, tutti i filtri sono contemporaneamente attivi e operano in modalità pull-push, concorrente e asincrona. A differenza degli scenari precedenti ciascun filtro vive in un processo o thread separato, e le pipe possono essere asincrone. Ciascuna pipe qui svolge anche il ruolo di buffer, e si occupa di sincronizzare i filtri che collega. Le pipe sono anche delle indirezioni che riducono l’accoppiamento tra i filtri che collegano, e i filtri quindi (solitamente) non conoscono l’identità dei filtri adiacenti. Questo apre la strada a diverse soluzioni volte a migliorare la flessibilità (o meglio: modificabilità) della pipeline: un filtro continuerà ad inviare dati verso la pipe successiva, se poi dopo quella pipe c’è un filtro, un altro oppure la destinazione dei dati, lui non se ne accorge neanche.
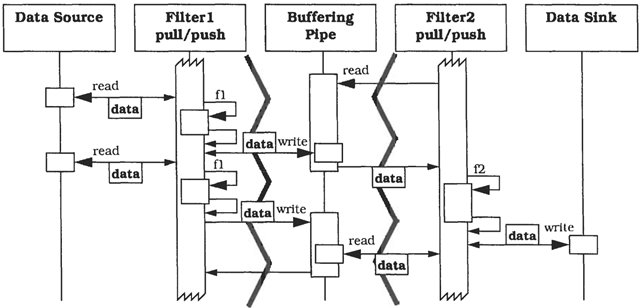
Dei quattro scenari presentati questo è quello che permette prestazioni migliori: dal momento che ciascun filtro vive in un processo o thread separato ognuno di essi può svolgere il proprio compito indipendentemente dagli altri, con l’ulteriore vantaggio che del buffering dei dati, se ne occupano le pipe (che ci potrebbero essere messe a disposizione da strumenti di Messaging come RabbitMQ.
IMPATTI
Come ogni pattern architetturale anche pipes and filters ha impatti sulle diverse qualità del sistema, e se si decide di implementarlo bisogna tenere a mente le sue conseguenze sul sistema, senza farsi prendere dalla sindrome del martello (“Quando hai un martello in mano vedi chiodi dappertutto”).
• Si può realizzare una nuova trasformazione semplicemente ridefinendo la pipeline, a vantaggio della modificabilità della trasformazione operata dal sistema
• La possibilità di aggiungere, sostituire, modificare o rimuovere filtri, e il loro disaccoppiamento tramite pipe vanno a vantaggio della flessibilità del sistema
• Qualora un nuovo filtro richieda una modifica a cascata sui filtri successivi (ad esempio per gestire un nuovo campo in un JSON), oppure qualora non si abbia a disposizione una buona libreria di filtri, modificare la pipeline può risultare problematico
• Lo scenario 4, aprendo la possibilità di scrivere codice concorrente, può andare a vantaggio delle prestazioni
• Si possono avere più istanze dello stesso filtro, che operano in parallelo
• Le pipe sono delle unità di buffering, e questo elimina la necessità di sincronizzazione tra filtri, salvo casi particolari
• La concorrenza non sempre va a vantaggio delle prestazioni: in questo caso abbiamo tuttavia un overhead dovuto al continuo trasferimento dei dati tra filtri, al cambio di contesto e al diverso formato dei dati, che può avere anzi l’effetto contrario
• Non è facile fare considerazioni generali, perché l’affidabilità dipende in larga misura dalla tipologia della pipeline
• Spesso i dati devono essere elaborati da molti filtri, e questo può rendere difficile la verificabilità dell’intero sistema (anche se è relativamente facile verificare ogni filtro in isolamento)
• Possiamo aumentare l’affidabilità facendo uso di un message broker affidabile, come RabbitMQ.
• I sistemi e i componenti Pipes and filters sono normalmente basati su un’interfaccia piccola e ben definita, quindi con minori possibilità di usi non autorizzati
• C’è la possibilità di introdurre meccanismi di sicurezza sull’intero sistema o sui singoli componenti
• È possibile riusare i filtri, e andare così a comporre una propria libreria di filtri
• La condivisione di dati tra più elementi può essere difficile (cosa succede se più filtri devono accedere concorrentemente a dati su disco?)
• La gestione degli errori di solito è difficoltosa. Un esempio comune di sistema Pipes&Filters è dato dai compilatori. Si pensi a quante volte vengono segnalati più errori di compilazione quando in realtà ce n’è uno solo, o quante volte viene segnalato un errore al posto di un altro.
ESEMPIO
Per comprendere meglio i concetti illustrati mostreremo ora i punti salienti dell’implementazione di Pipes & filters proposta da Microsoft. Si tratta di un’implementazione specifica per Azure che sfrutta alcuni suoi strumenti (come il Service Bus), ma il nucleo concettuale resta lo stesso.
Può essere interessante andare ad esaminare la classe ServiceBusPipeFilter, che non è altro che un connettore tra due filtri. In particolare, il metodo OnPipeFilterMessageAsync si occupa di ricevere messaggi dalla coda e fare un push al prossimo filtro per avere un messaggio elaborato da inviare alla prossima coda.
public void OnPipeFilterMessageAsync(Func<ServiceBusReceivedMessage, Task<ServiceBusMessage» asyncFilterTask)
{
this.processor.ProcessMessageAsync +=
async args =>
{
ServiceBusReceivedMessage message = args.Message;
pauseProcessingEvent.WaitOne();
if (message.DeliveryCount > Constants.MaxServiceBusDeliveryCount)
{
await args.DeadLetterMessageAsync(message);
Trace.TraceWarning("Maximum Message Count Exceeded: {0) for MessageID: {1) ", Constants.
MaxServiceBusDeliveryCount, message.Messageld);
return;
}
var outMessage = await asyncFilterTask(message);
if (sender != null)
{
await this.sender.SendMessageAsync(outMessage);
}
});
this.processor.ProcessErrorAsync += this.OptionsOnExceptionReceived;
this.processor.StartProcessingAsync();
}Si può notare che, come abbiamo detto, si tratta di implementazione un po’ diversa da quella “canonica”, dal momento che è la pipe che si occupa di inviare dati alla coda successiva invece che il filtro, che nella versione proposta nel catalogo POSA è colui che fa push verso la pipe e quindi verso il filtro successivo.
Il secondo elemento da analizzare è la classe PipeFilterARoleEntry.
public override bool OnStart()
{
ServicePointManager.DefaultConnectionlimit = 12;
this.pipeFilterA = new ServiceBusPipeFilter(
Settings.ServiceBusConnectionString,
Constants.QueueAPath,
Constants.QueueBPath);
this.pipeFilterA.Start();
return base.OnStart();
} public override void Run()
{
this.pipeFilterA.OnPipeFilterMessageAsync(async (msg) =>
{
var newMsg = new ServiceBusMessage(msg);
await Task.Delay(500);
Trace.TraceInformation("Fitler A processed message:{0} at {1}", msg.Messageld, DateTime.UtcNow);
newMsg.ApplicationProperties.Add(Constants.FilterAMessagekey, "Complete");
return newMsg;
});
this.stopRunningEvent.WaitOne();
} Non è molto importante la logica del filtro (non fa altro che fare un clone del messaggio ricevuto), quanto la scelta degli “strumenti”. Qui i filtri vengono implementati come WorkerRole, e questo significa che ogni filtro può scalare indipendentemente dagli altri, qualora gli sia richiesta potenza di calcolo maggiore. Inoltre, più istanze di un singolo WorkerRole possono essere eseguite in parallelo, a vantaggio del throughput.
L’esempio riporta anche due ruoli addizionali chiamati InitialSenderRoleEntry e FinalReceiverRoleEntry. InitialSenderRoleEntry produce il primo messaggio nella pipeline, tramite i metodi OnStart (per connettersi alla coda) e Run (per pubblicare messaggi su di essa). La classe FinalReceiverRoleEntry è la destinazione finale dei messaggi:
public override bool OnStart()
{
ServicePointManager.DefaultConnectionLimit = 12;
this.queueFinal = new ServiceBusPipeFilter(Settings.ServiceBusConnectionString,
Constants.QueueFinalPath);
this.queueFinal.Start();
return base.OnStart();
}public override void Run()
{
this.queueFinal.OnPipeFilterMessageAsync(
async (msg) =>
{
await Task.Delay(500);
Trace.TraceInformation(
"Pipeline Message Complete - FilterA:{0} FilterB:{1}",
msg.ApplicationProperties[Constants.FilterAMessageKey],
msg.ApplicationProperties[Constants.FilterBMessageKey]);
return null;
});
this.stopRunningEvent.WaitOne();
}Anche le ultime due classi presentate sono implementare come WorkerRole, quindi beneficiano di tutti i vantaggi circa scalabilità e possibile parallelismo visti per PipeFilterARoleEntry e PipeFilterBRoleEntry.
Fonti e Bibliografia
Questo articolo è basato su “Luca Cabibbo. 2021. Architettura del software – strutture e qualità. Edizioni Efesto”.
Il pattern Pipes and Filters è stato trattato in “Frank Buschmann, Regine Meunier, Hans Rohnert, Peter Sommerlad, and Michael Stal. 2008. Pattern-oriented software architecture: A system of patterns. John Wiley & Sons.”, da cui sono stati tratti i diagrammi di sequenza.
L’implementazione di Pipes & filters proposta da Microsoft è reperibile all’indirizzo https://docs.microsoft.com/en-us/azure/architecture/patterns/pipes-and-filters.


Pierpaolo Paris
Sono uno sviluppatore cresciuto col mito di quelli che nei telefilm e nei cartoni animati degli anni ‘80/90 con una tastiera risolvevano i problemi del mondo (non si sa bene come, ma lo facevano). Ci ho provato anche io, ma una volta scoperto di non poter seguire le orme dei miei eroi ho deciso di accontentarmi di scrivere del buon codice.
Last modified: April 23, 2024






